

Introduction
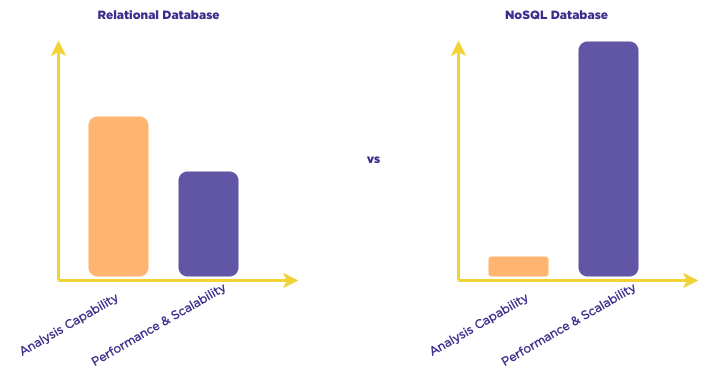
Fairmint provides a complete stakeholder back-end for companies to conduct Rolling SAFE offerings, enabling them to raise funds continuously, implement automated incentivization plans, and allow supporters to purchase and earn equity in a compliant manner. Their platform leverages Amazon Web Services' (AWS) on-demand DynamoDB, a fully managed NoSQL database service. This service is specifically chosen for its ability to offer high scalability, flexibility, and low latency, making it ideal for applications that require quick response times in the millisecond range. DynamoDB follows a key-value store architecture, allowing users to store and retrieve data through simple API calls.
Fairmint employs the recommended "Single-Table Design" by Alex DeBrie (for more information:
The What, Why, and When of Single-Table Design with DynamoDB
) when using DynamoDB. This approach involves consolidating all application data into a single table, rather than distributing it across multiple tables. This design promotes the use of a primary key with a composite sort key, enabling flexible querying and reducing the need for complex data joins. By embracing this design principle, Fairmint ensures an efficient and high-performance application.
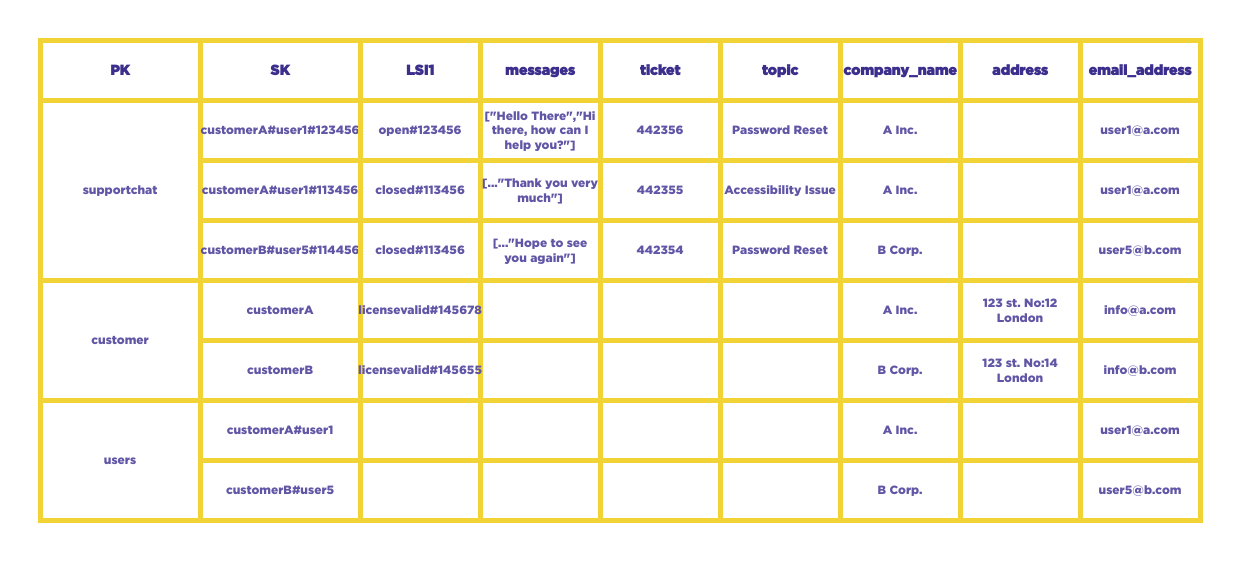
In the example above, there are three separate entities: support chat, customers, and users. At present, not all attributes are being fully utilized, and the data types within the same attribute may vary. Nevertheless, these entities are all designed to accommodate application access patterns. By specifying the user's ID and ticket number in a single API call, the application is able to retrieve all the messages from the support chat.
The Problem
The challenge arises when we need to analyze or summarize the data that has been de-normalized to work efficiently with DynamoDB, as explained earlier. This de-normalization process makes the data complex, to the point where retrieving a single number requires string parsing. While this ensures smooth functioning of our application, it can be perplexing for data scientists who are accustomed to working with normalized data.
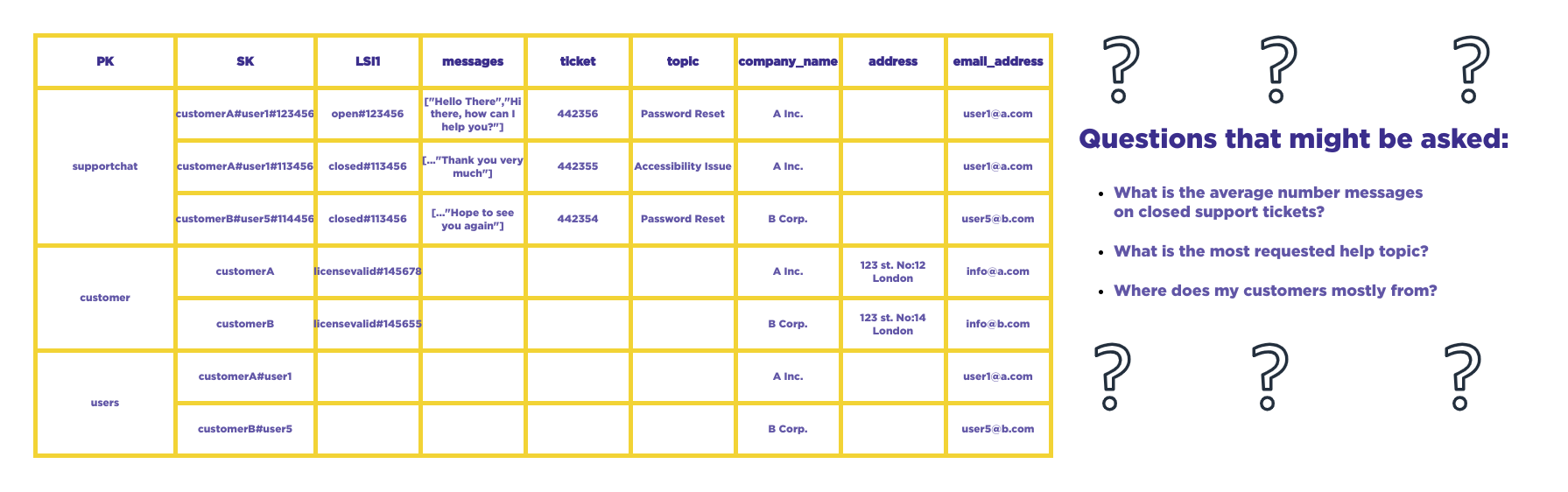
Furthermore, the "scan" operation in DynamoDB is the most costly. DynamoDB functions like a large "hash-map" and only knows the locations of specific indexed values. The problem arises when we need to access data without knowing its specific index, as we have to search through the entire database.
When designing the application, it is generally recommended to minimize the use of the scan operation. However, there are situations where avoiding the scan operation becomes unavoidable. For instance, if data scientists require retrieving every person above the age of 35, using the scan operation may be necessary in such cases.
The Solution
The methodology for this solution can be outlined as follows:
- Create a schema that encompasses all attributes of the objects.
- Perform periodic scans of the entire table.
- Normalize the data after the scanning process.
To implement these principles effectively, it is important to consider the appropriate toolset:
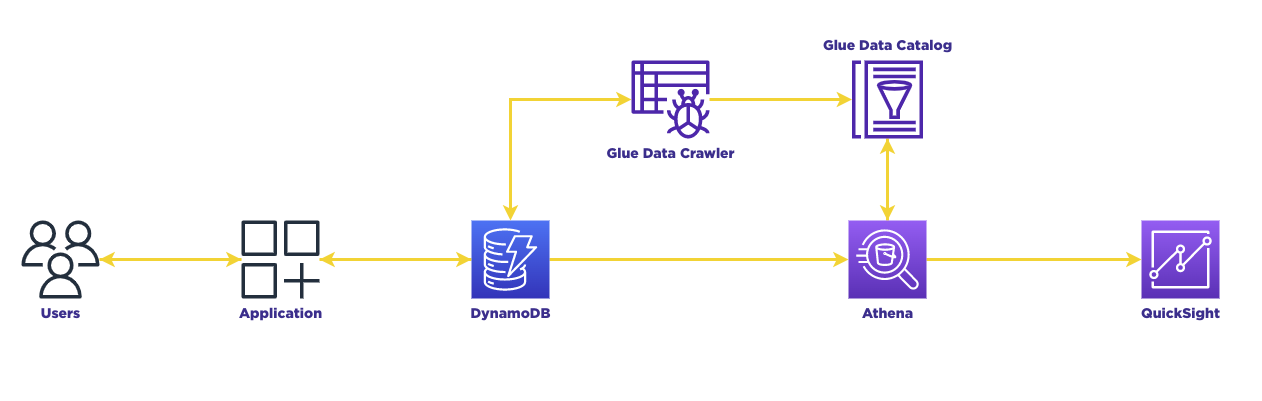
Components
AWS Glue Crawler
To create the schema, we will utilize AWS Glue Crawler. This tool allows us to scan the table and perform the following actions to explore a data store:
- Classify the data: AWS Glue Crawler determines the format, schema, and properties of the raw data by classifying it. You can customize the classification process by creating a custom classifier.
- Group data: The tool uses crawler heuristics to group the data into tables or partitions based on certain criteria.
- Write metadata to the Data Catalog: AWS Glue Crawler adds, updates, and deletes tables and partitions in the Data Catalog, ensuring that the metadata is properly maintained.
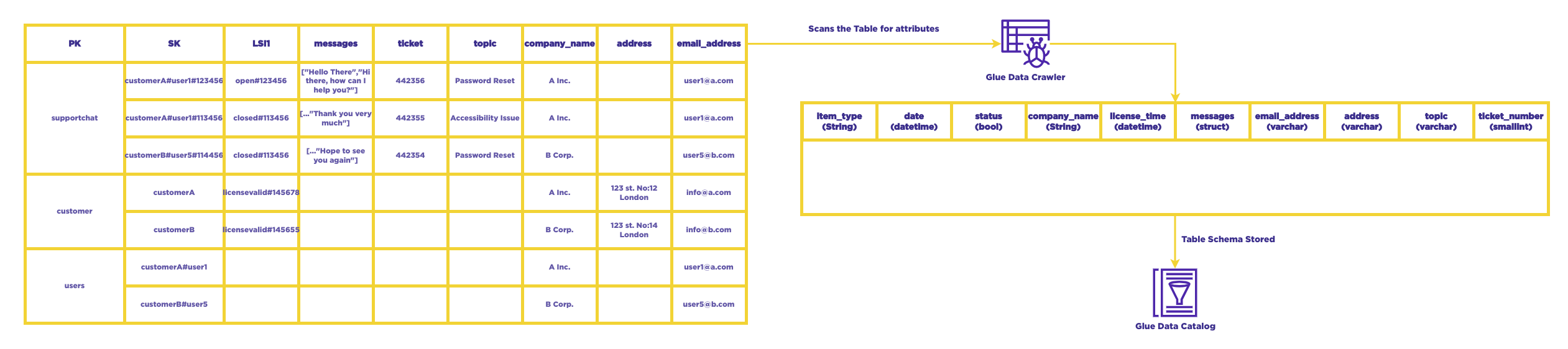
AWS Athena
Amazon Athena is a powerful query service that enables users to analyze data directly from various sources. It simplifies the analysis of unstructured or semi-structured data stored in different formats. With Athena, users can run on-demand queries using standard SQL, eliminating the need to aggregate or load data into the service.
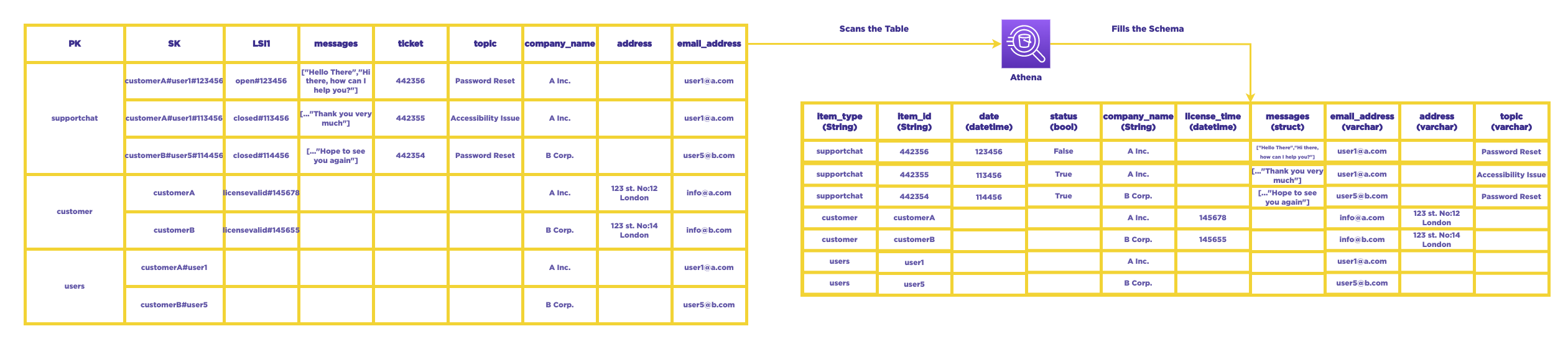
By leveraging AWS Glue Crawler, we can effectively scan the DynamoDB and transform each row into a tabular format. This allows us to seamlessly pass the entire data to our Business Intelligence tool, QuickSight, without any compromises. QuickSight can then efficiently process and visualize the data for further analysis.
AWS QuickSight
Once the data is transformed into a tabular format, we can proceed to load this data into QuickSight, utilizing its data integration capabilities including AWS Athena. However, it is crucial that the data being loaded is targeted towards SPICE, which is QuickSight's powerful in-memory engine. This is done to minimize the need for scanning the DynamoDB table repeatedly.
By storing the periodic scan results in SPICE, we can efficiently perform data modifications, calculations, and queries on this engine. QuickSight allows for dataset generation from existing tables and provides the flexibility to calculate, modify, and extract rows or columns individually. This enables us to normalize the data and create a tabular structure per object type within QuickSight.
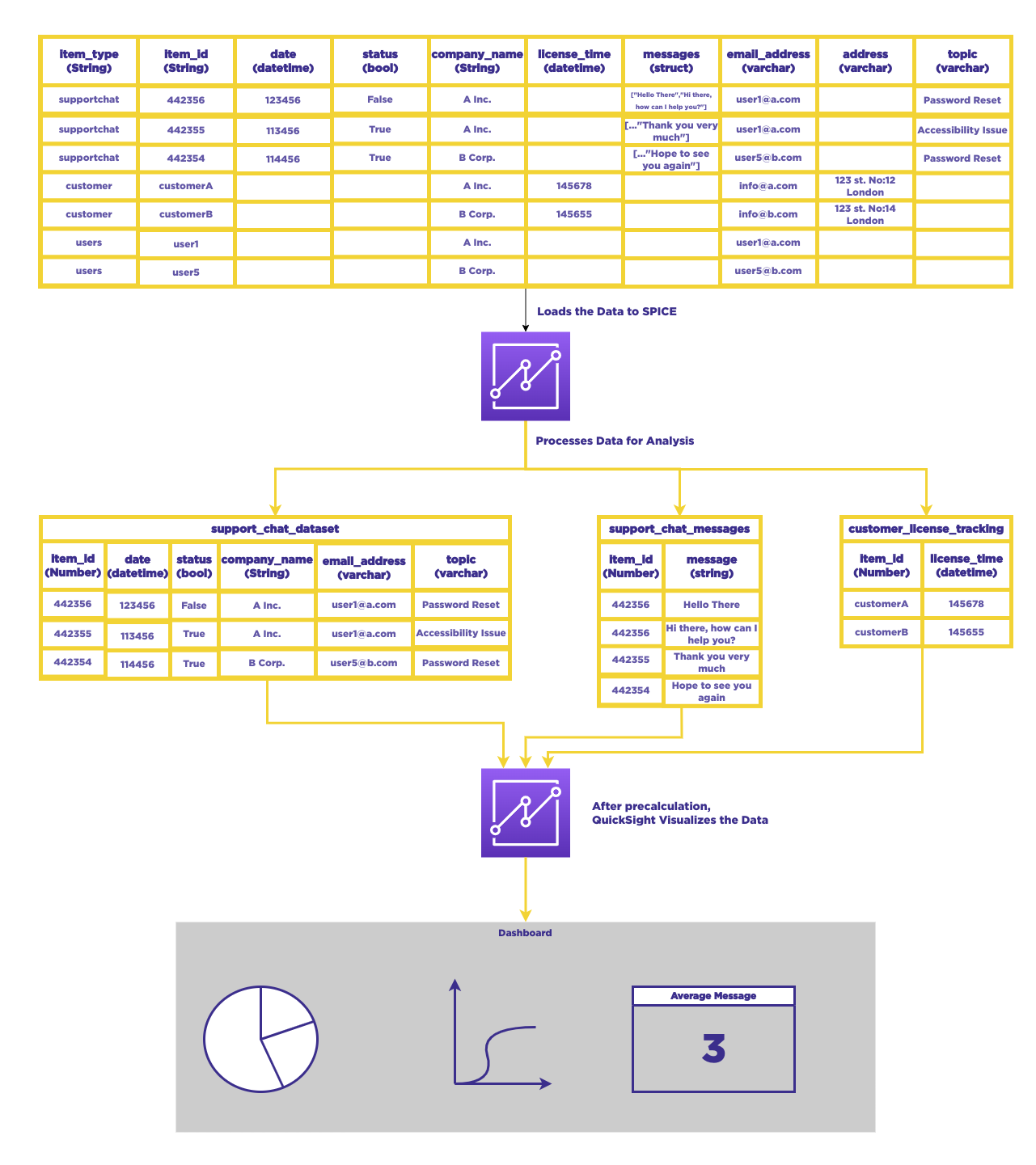
The Effect
By establishing this data pipeline, Fairmint provides both its management and customers with the ability to analyze their respective data without affecting the application's performance or availability. This setup fosters the use of advanced analytics tools and techniques such as tabular aggregation, calculations spanning entire columns, and parsing geolocation data for spatial analysis.
In conclusion, the systematic use of AWS services like DynamoDB, AWS Glue Crawler, Amazon Athena, and QuickSight, enables Fairmint to create an efficient and performance-driven application. By turning complex data into a user-friendly tabular format, Fairmint provides valuable insights to its management and customers.
How can we help?
Sonne Technology, founded in 2021, is a leading provider of precision-crafted AWS solutions that revolutionize cloud computing. Leveraging our AI-powered expertise , we specialize in tailoring solutions to meet the unique business needs of our clients. With a focus on delivering Function as a Service (serverless) products, we ensure an easy-to-manage, stress-free experience. Our specialized services cater to startups and SMEs , prioritizing flexibility and cost-effectiveness. We thrive in an ultra-agile environment, ready to tackle any challenge. Join us and transform your cloud experience.
