

AWS SageMaker JumpStart offers ready-to-use solutions for various machine learning use cases, allowing users to quickly get started with machine learning. The platform provides pretrained, open-source models that can be customized and fine-tuned before deployment. Additionally, SageMaker JumpStart offers solution templates and example notebooks to help users set up infrastructure and implement machine learning projects with ease.
Accessing JumpStart
To access JumpStart in Amazon SageMaker Studio, users can navigate to the JumpStart landing page from either the Home page or the Home menu on the left-side panel. From the Home page, users can choose JumpStart in the Prebuilt and automated solutions pane. Alternatively, they can select a specific model in the JumpStart pane or choose Browse all JumpStart to access the SageMaker JumpStart landing page.
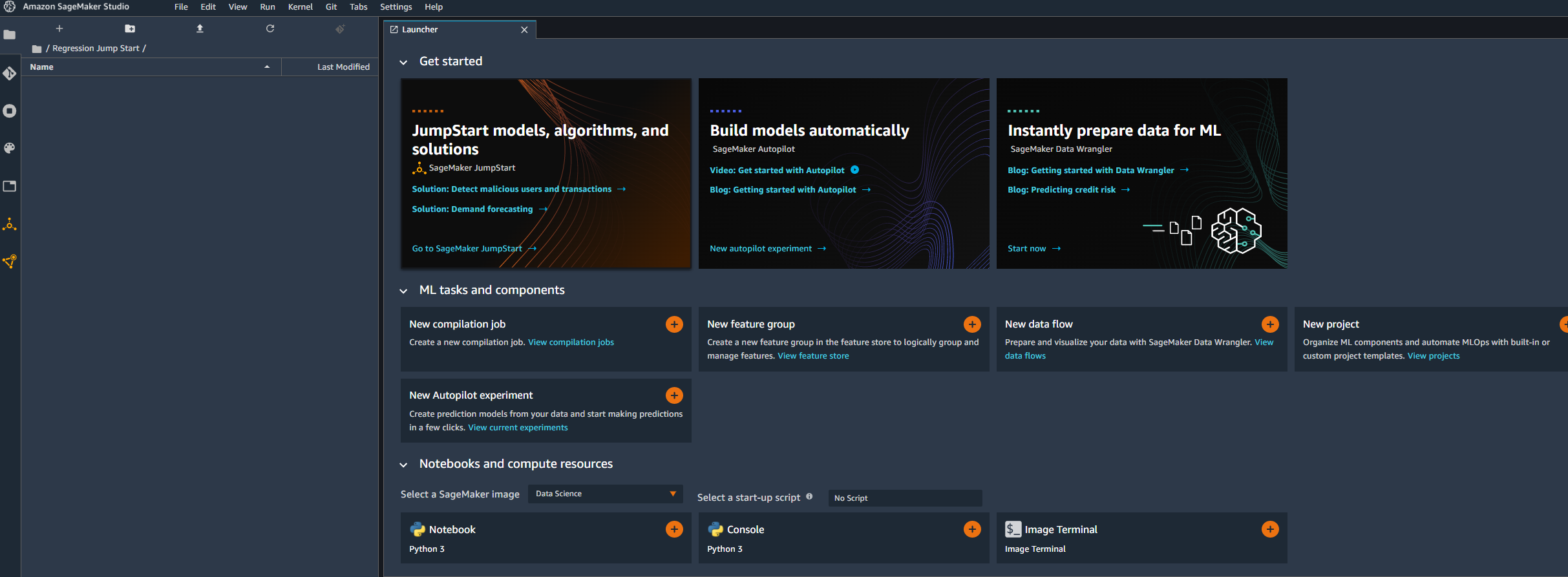
Utilizing JumpStart
On the SageMaker JumpStart landing page, users can explore a wide range of solutions, models, notebooks, and other resources.
Solutions:
The Solutions section allows users to launch comprehensive machine learning solutions that integrate with other AWS services. By selecting Explore All Solutions, users can view all available solutions.
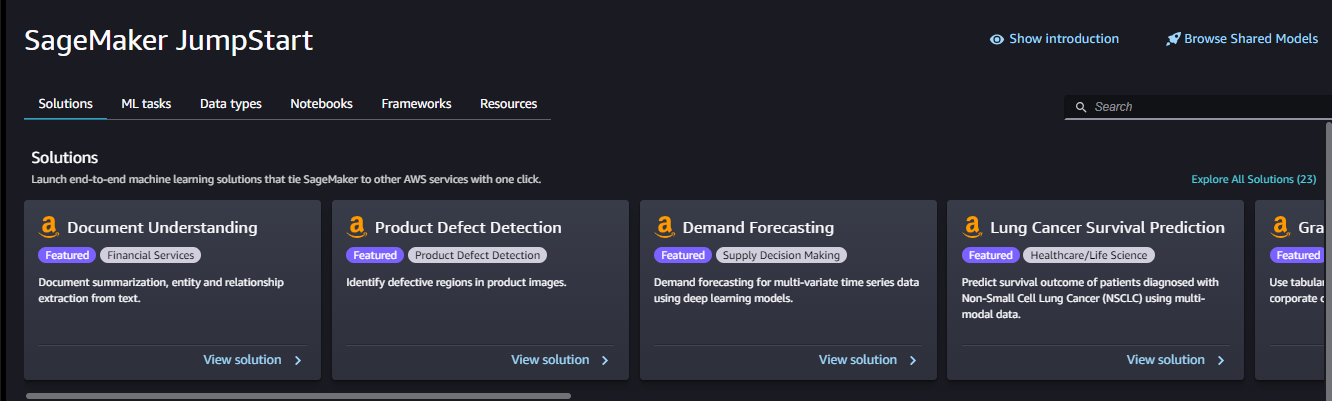
For example, if you choose Demand Forecasting which uses historical time series data in order to make future estimations in relation to customer demand over a specific period and streamline the supply-demand decision-making process across businesses, just select Demand Forecasting with Deep Learning and launch it by pressing “Launch” button.
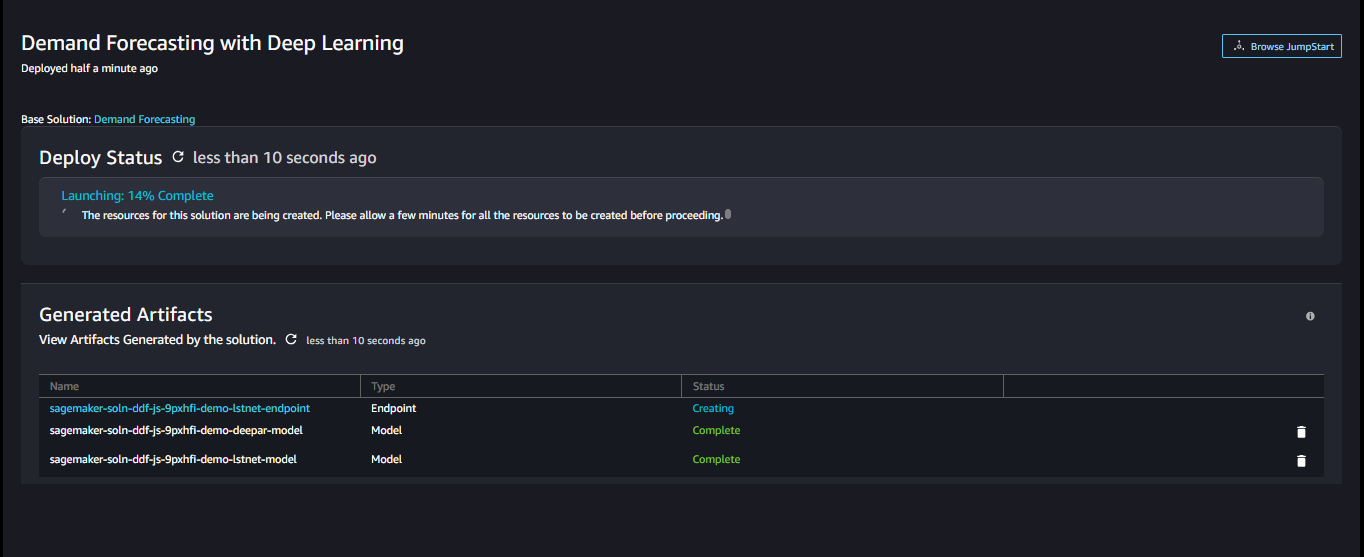
It takes a little time then your solution will be ready to use.
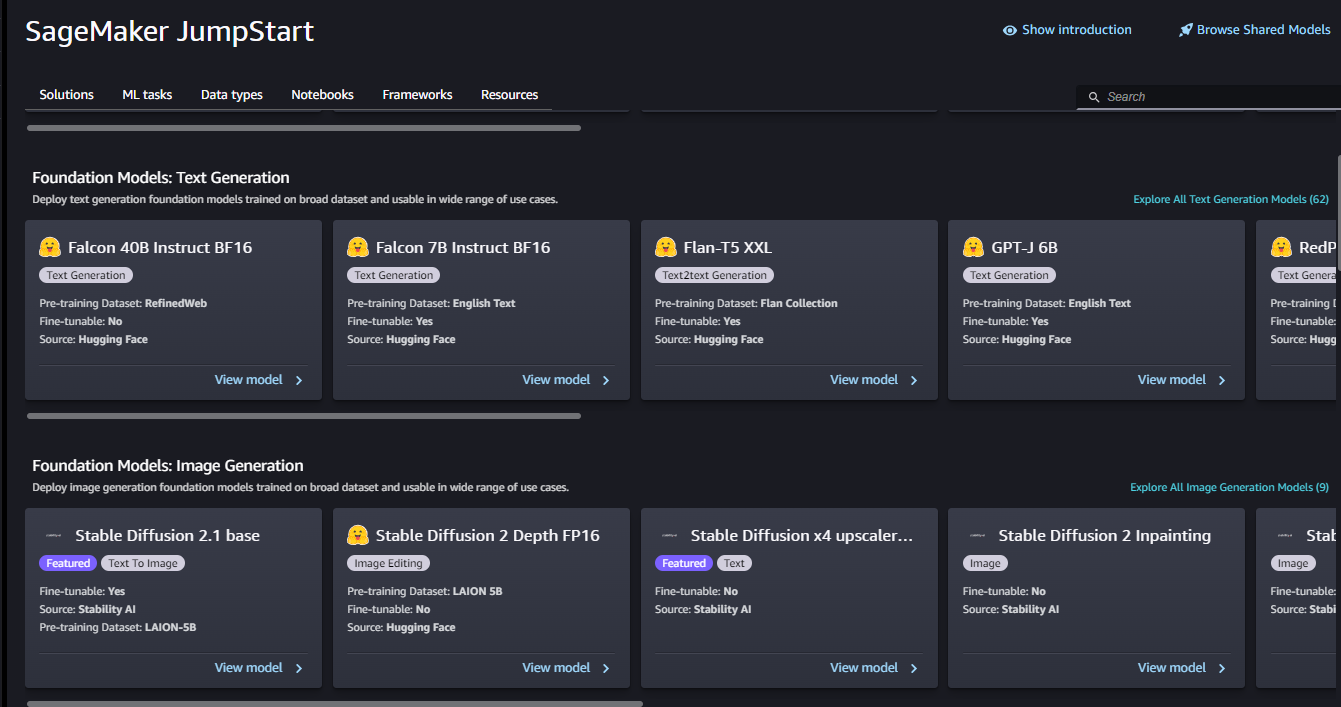
Foundation Models:
For users looking for foundation models, SageMaker JumpStart offers state-of-the-art models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.

These foundation models can be used as a starting point to build generative AI solutions tailored to specific business needs.
Machine Learning tasks:
To find a model based on a specific problem type, such as Image Classification, Image Embedding, Object Detection, or Text Generation, users can select Explore All Models on the JumpStart landing page. This allows them to search and browse through the available models. When a model is selected, users can access the model detail page, which provides in-depth information about the model. This includes details on what the model can do, the expected input and output types, and the data requirements for fine-tuning the model.
| Problem types | Supports inference with pre-trained models | Trainable on a custom dataset | Supported frameworks |
|---|---|---|---|
| Image classification | Yes | Yes | PyTorch, TensorFlow |
| Object detection | Yes | Yes | PyTorch, TensorFlow, MXNet |
| Semantic segmentation | Yes | Yes | MXNet |
| Instance segmentation | Yes | Yes | MXNet |
| Image embedding | Yes | No | TensorFlow,MXNet |
| Text classification | Yes | Yes | TensorFlow |
| Sentence pair classification | Yes | Yes | TensorFlow, HuggingFace |
| Question answering | Yes | Yes | PyTorch, HuggingFace |
| Named entity recognition | Yes | No | HuggingFace |
| Text summarization | Yes | No | HuggingFace |
| Text generation | Yes | No | HuggingFace |
| Machine Translation | Yes | No | HuggingFace |
| Text embedding | Yes | No | TensorFlow,MXNet |
| Tabular classification | Yes | Yes | LightGBM, CatBoost, XGBoost, AutoGluon-Tabular, TabTransformer, Linear Learner |
| Tabular regression | Yes | Yes | LightGBM, CatBoost, XGBoost, AutoGluon-Tabular, TabTransformer, Linear Learner |
Model deployment configuration
After you choose a model, the model's tab opens. In the `Deploy Model` pane, choose`Deployment Configuration` to configure your model deployment.
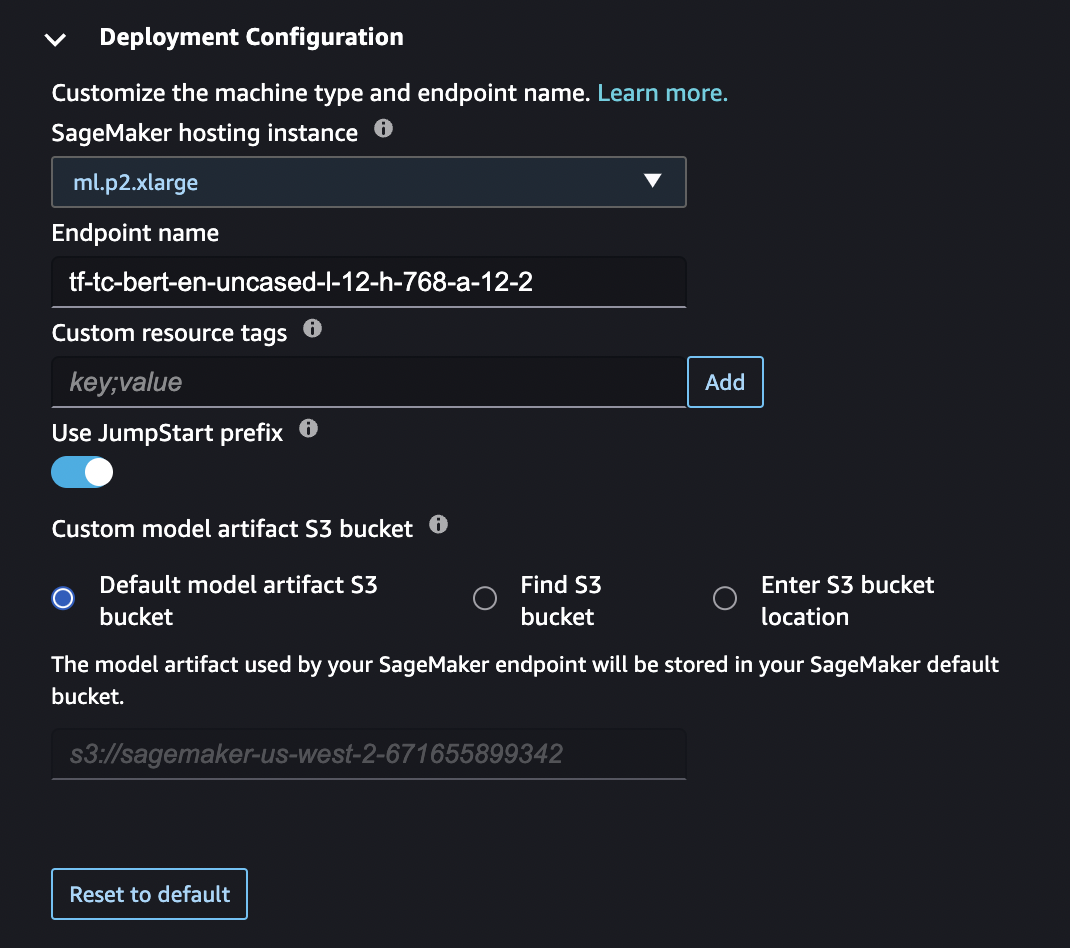
You can also change the endpoint name, add `key;value` resource tags, activate or deactive the `jumpstart-` prefix for any JumpStart resources related to the model, and specify an Amazon S3 bucket for storing model artifacts used by your SageMaker endpoint.
Fine-Tuning data source
When you fine-tune a model, you can use the default dataset or choose your own data, which is located in an Amazon S3 bucket.
To browse the buckets available to you, choose `Find S3 bucket`. These buckets are limited by the permissions used to set up your Studio account. You can also specify an Amazon S3 URI by choosing `Enter Amazon S3 bucket location`.

For text models:
- The bucket must have a data.csv file.
- The first column must be a unique integer for the class label. For example: 1, 2, 3, 4, n
- The second column must be a string.
- The second column should have the corresponding text that matches the type and language for the model.
For vision models:
- The bucket must have as many subdirectories as the number of classes.
- Each subdirectory should contain images that belong to that class in `.jpg` format.
Conclusion
Overall, AWS SageMaker JumpStart streamlines the process of getting started with machine learning by offering pretrained models, solution templates, and example notebooks. This allows users to quickly implement machine learning projects and customize models to suit their business needs, ultimately accelerating the development and deployment of AI solutions.
