

Introduction
TrackTrack is an information analytics platform that necessitates a system capable of downloading extensive .pdf files from publicly available websites. This system is required to internally process these files to identify any changes in regulations across multiple countries pertaining to the development of railway infrastructure in the Eurasian region.
However, these files are quite large, ranging from 1 to 5 GB in size. Unfortunately, the internet connectivity in the region is not stable enough to allow for a single, uninterrupted download of these files. Alternatively, even if a download is possible, the slow transfer rate would significantly prolong the download process, making it exceptionally time-consuming.
To resolve this issue, we will rely on three key features:
- HTTP Content-Length Headers,
- S3 Byte Stream IO API,
- and S3 Multipart Upload.
Firstly, by extracting the file size using the HTTP Content-Length Headers feature, we can divide the download task into smaller, more manageable segments.
Secondly, the S3 Byte Stream IO API will enable us to directly upload each segment to S3 without requiring the files to be downloaded locally. This will facilitate the seamless and efficient transfer of data to the S3 bucket.
Finally, we will use the S3 Multipart Upload feature to upload the file in multiple chunks and then merge them together to complete the download process. This feature ensures that even if the internet connectivity is not stable, the download process will not be interrupted, and all data will be uploaded to the S3 bucket without any loss.
Architecture
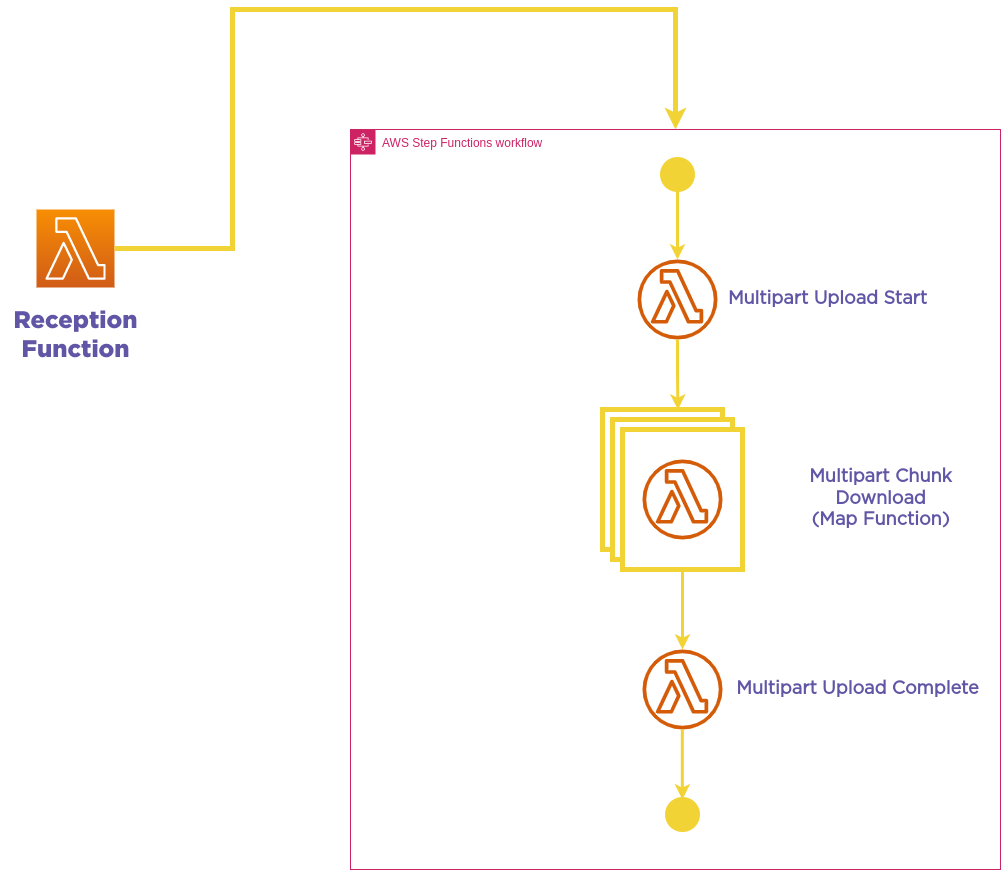
To achieve this goal, we will require four distinct components:
- Reception Function: This function retrieves the HTTP headers of the file and decides how many parts to download the file in. In case the content-length header is not found, it will begin the direct download of the file.
- Multipart Upload Start: This function creates the S3 manifest and assigns the download workers with the specific parts they will be downloading.
- Chunk Download Function: This function streams the assigned bytes to S3 as separate parts.
- Multipart Upload Complete Function: This function initiates the merging of all parts and completes the S3 download operation.
Implementations
Reception Function
To gather the `Content-Length` of the file, we will need to import the `urllib` library. This will enable us to extract the headers from the URL and retrieve the content-length value, which is necessary for dividing the file download into smaller segments.
#Initial imports and defining the URL
import math
from urllib import request as http_req
file_url = ""
# Prepare the HTTP Request
request_object = http_req.urlopen(file_url)
# Get the Headers of the file
request_object_headers = dict(request_object.getheaders())
# Convert Headers into one schema and index them inside one dict
lowercase_request_object_headers = {key.lower():value for key,value in request_object_headers.items()}
# Check Content Type and its header
if "content-type" in lowercase_request_object_headers.keys():
if "application/pdf" in lowercase_request_object_headers["content-type"].lower():
logger.info("Content Type is suitable")
else:
raise Exception("Content Type is not suitable")
else:
raise Exception("Content Type header does not exist!")
# First define a partinioning function
def url_partition_list(content_length:int) -> int:
logger.info("Chunks will be 125 MBs per function")
if content_length > 131072000:
return math.ceil(content_length/131072000)
else:
return 1
# Then now you can divide file into chunks and get the partion count
if "content-length" in lowercase_request_object_headers.keys():
if lowercase_request_object_headers["content-length"]:
logger.info("Getting the partition count")
partition_count = url_partition_list(int(lowercase_request_object_headers["content-length"]))
logger.info("Partition count is {}".format(partition_count))
else:
raise Exception("File is 0 byte")
else:
logger.warning("File size unknown, multipart data stream is not possible")
Great! With this information, we can now begin to develop the Step Function that will execute the four components we have outlined. We can utilize AWS Lambda functions for each component and integrate them using AWS Step Functions. This will enable us to automate the entire process, making it faster, more efficient, and less prone to errors.
Multipart Upload Start
To initiate the multipart upload process, we will first need to generate an UploadID from S3 using the boto3 library in Python. This will enable us to create a manifest that will keep track of all the parts of the file that are being uploaded separately. Once the manifest is created, we can assign the download workers with the specific parts they will be downloading using the manifest.
# Initiating S3 Client
s3_client = boto3.client('s3')
# Getting the UploadID for the S3 Multipart
multipart_upload_id = s3_client.create_multipart_upload(
Bucket=bucket_name,
Key="{}.pdf".format(hashlib.sha1(file_url.encode()).hexdigest())
)['UploadId']
Now that we have obtained the Multipart Upload ID, we can generate a list of task manifests for each lambda chunk download function using the generate_download_partition function.
def generate_download_partition(file_url,partition_count,multipart_upload_id,file_size):
increment_byte = file_size/partition_count
for partition in range(partition_count):
if partition == 0:
start_byte = 0
end_byte = math.floor(increment_byte)
elif partition+1 == partition_count:
start_byte = end_byte+1
end_byte = file_size
else:
start_byte = end_byte+1
end_byte = math.floor((partition+1)*increment_byte)
yield {
"url":file_url,
"start":start_byte,
"end":end_byte,
"upload_id":multipart_upload_id,
"file_size":file_size,
"partition_number":partition+1
}
Let me clarify what the generate_download_partition function does.
Firstly, it calculates the increment byte for each partition, which is then used to divide the file into smaller chunks. The first partition always starts at 0, and the increment byte is rounded down to the nearest integer.
For all other partitions, the start byte is equal to the increment byte plus one, due to rounding. The end byte of the last partition is equal to the content length of the file since it represents the total number of bytes in the file.
In summary, this function divides the file into multiple partitions of equal size, except for the last partition, which may be smaller in size if the file size is not evenly divisible by the number of partitions.
Once the task manifests have been generated for each partition, they are sent to the chunk download function. This function then triggers the Lambda functions in parallel, allowing multiple chunks to be downloaded simultaneously.
Chunk Download Function
Using the manifest generated earlier, the chunk download function opens a stream using the urllib library and specifies the bytes to be retrieved from the file. Once the stream has been opened, it is passed to the S3 `upload_fileobj` function, which directly uploads the stream to S3 without downloading or waiting for the transfer to complete. This approach ensures a seamless transfer of data to the S3 bucket.
s3_client = boto3.client('s3')
file = http_req.Request(file_url)
file.add_header("Range","bytes={}-{}".format(start_byte,end_byte))
part_of_file = http_req.urlopen(file_url)
s3_client.upload_fileobj(part_of_file,bucket_name,"parts/{}".format(partition_number))
After the chunk have been successfully uploaded to S3, they can be submitted as part of the multipart upload operation to S3.
s3_client.upload_part_copy(
Bucket=bucket_name,
CopySource={
'Bucket':bucket_name,
'Key':"parts/{}".format(partition_number)
},
Key="{}.pdf".format(hashlib.sha1(file_url.encode()).hexdigest()),
PartNumber=partition_number,
UploadId=upload_id
)
Multipart Upload Complete
Once all the chunks have been uploaded, we can submit the multipart upload operation for completion and finalize the object upload from the internet to S3.
To complete the multipart upload operation, we first list the current parts that have been uploaded, remove several keys from the response, and pass the remaining responses as a list to the completion function. This function will then merge the parts together to form the complete file and complete the upload operation to S3.
s3_client = boto3.client('s3')
parts = s3_client.list_parts(
Bucket=bucket_name,
Key="{}.pdf".format(hashlib.sha1(file_url.encode()).hexdigest()),
UploadId=upload_id
)['Parts']
for part in parts:
del part['LastModified']
del part['Size']
s3_client.complete_multipart_upload(
Bucket=bucket_name,
Key="{}.pdf".format(hashlib.sha1(file_url.encode()).hexdigest()),
MultipartUpload={
'Parts':parts
},
UploadId=upload_id
)
Conclusion
To conclude, TrackTrack now has a fault-tolerant system that ensures the successful download of large files from public websites. With the ability to divide the download job into smaller chunks, upload them to S3 via the byte stream IO API, and merge them together using the multipart upload feature, the system is capable of overcoming unstable internet connectivity and slow transfer rates.
This new system has significantly reduced operational overhead, as compared to the previous approach, which relied on servers to download the files. Moreover, TrackTrack can now start processing the downloaded files as soon as the download is completed, ensuring that the system is more responsive and efficient. Overall, this new system has proven to be a cost-effective and reliable solution for TrackTrack's specific requirements.
Who are we?
Sonne Technology was founded in 2021 with the mission of providing cloud based solutions and consultancy services to businesses. Our focus is on creating Function as a Service (Serverless) products that offer customers an easy-to-manage, stress-free experience. We specialize in working with startups and SMEs, where flexibility and cost-effectiveness are key. Our team is ready to take on any challenge in an ultra-agile environment. We are dedicated to creating a community of growth and mutual support.
