

In my previous blog post, I discussed the potential of utilizing vectorization to achieve a semantic search, as well as the ability to establish a contextual framework with these vectors. Now, let's delve into the specific components that are crucial for initiating your semantic search.
There are three key factors to consider when setting up your neural search capabilities:
- Embedding Model
- Search Algorithm
- Vector Database
By carefully selecting and integrating these three components, you can establish a robust neural search system. Now, let's delve into each of these components in more detail.
Components
Embedding Model
As mentioned in our previous blog post, embedding models are sophisticated models designed to transform various forms of media (such as text, images, audio, or video) into numerical representations. One notable advantage of these models is that they can capture not only the content but also the contextual meaning embedded within. This is achieved by training the models to discern not only individual words but also the overall meanings of the text in the case of a text embedding model.
What to look for?
From an academic perspective, there are numerous factors to consider when evaluating an embedding model. However, when it comes to practical applications, I tend to prioritize three key aspects when selecting a model:
- Model Size
- Language Capabilities
- Average Score on MTEB Leader board
Model Size and Multi-Lingual Capabilities
There are indeed some remarkable embedding models available that require loading a significant 23 GB of binary data into memory. However, it is important to consider that such models can significantly increase processing time and resource consumption. In most production use cases, allocating such extensive resources is neither feasible nor encouraged unless absolutely necessary.
Hence, when selecting an embedding model for production applications, I suggest prioritizing minimal model size to optimize resource utilization. Here are several embedding models along with their respective model sizes:
| Model Name | Size | URL |
|---|---|---|
| intfloat/e5-large-v2 | 1.34 GB |
|
| sentence-transformers/all-MiniLM-L6-v2 | 90.9 MB |
|
| sentence-transformers/all-mpnet-base-v2 | 438 MB |
|
| intfloat/multilingual-e5-base | 1.11 GB |
|
| sentence-transformers/sentence-t5-xl | 2.48 GB |
|
| bigscience/sgpt-bloom-7b1-msmarco | 28 GB |
|
By opting for a smaller model size, you can strike a balance between memory requirements and processing efficiency, making it more feasible for deployment in resource-constrained production environments.
Indeed, many embedding models are trained exclusively using English datasets, making them unsuitable for handling other languages. To address this limitation, it is crucial to examine the language capabilities of a model before making a selection. For instance, the `intfloat/multilingual-e5-base` model demonstrates fluency in the following languages:

By considering the language fluency of a model, you can ensure that it aligns with the specific language requirements of your production use case, facilitating accurate and meaningful embedding for diverse linguistic data.
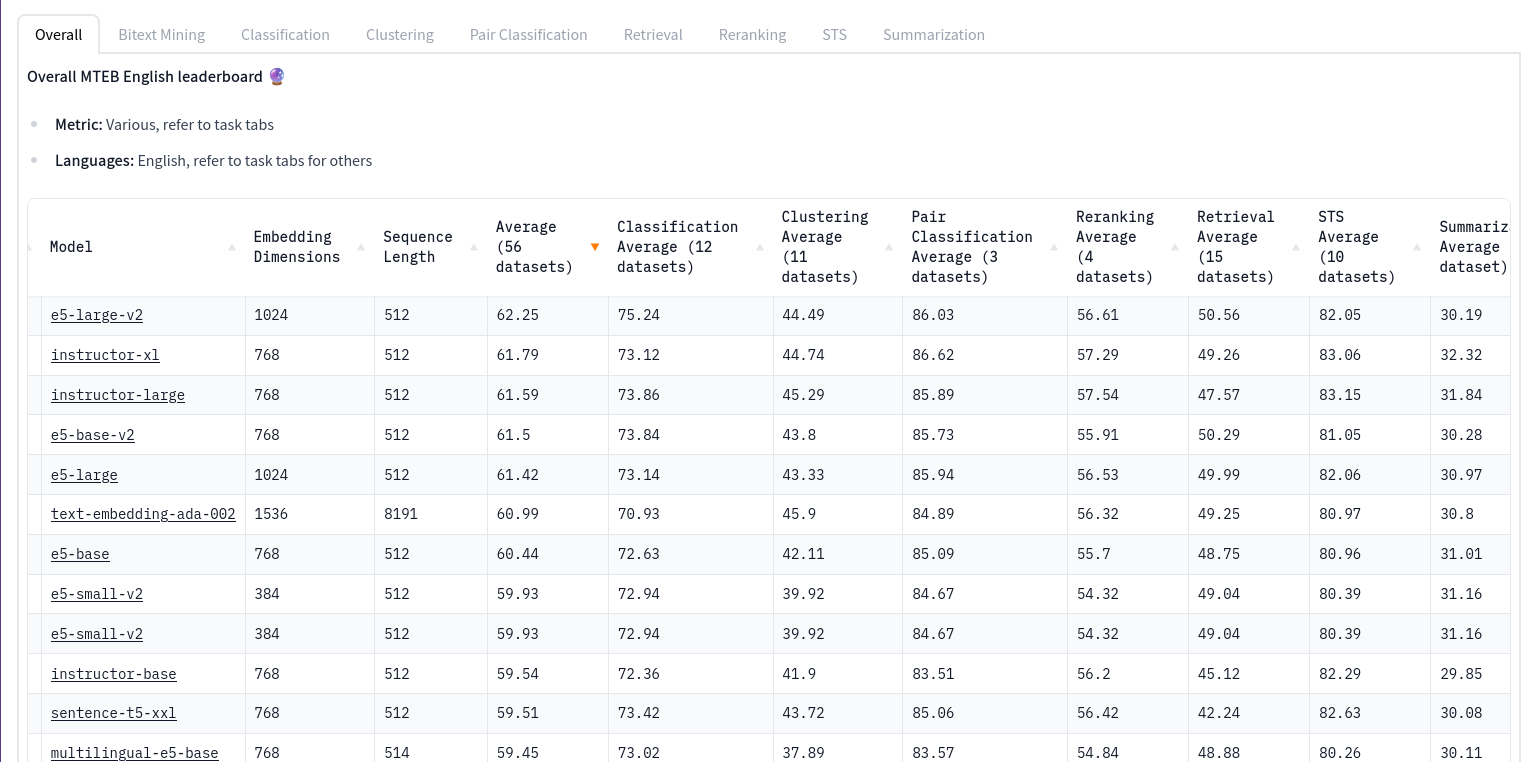
MTEB Leader board? What is that?
Massive Text Embedding Benchmark (MTEB) is a widely used evaluation test for assessing the accuracy and performance of various embedding models in a given task. It serves as a standardized benchmark to compare and evaluate the quality of different embedding models by measuring their ability to capture the semantic meaning of textual data. By analyzing the results of the MTEB, one can gain valuable insights into the accuracy and effectiveness of embedding models for specific tasks or applications.
You can view the up to date leader board here:
MTEB Leaderboard - Hugging Face
Search Algorithm
Choosing the appropriate search algorithm for neural search is imperative due to the resource-intensive nature of obtaining precise search results within the contextual space. Scanning each point individually is a costly process that can significantly impact user experience. As a result, employing an approximate search method enables us to deliver results efficiently while ensuring a seamless user interface. Despite the availability of numerous algorithm choices, we will focus on examining two promising options.
FAISS
FAISS, or Facebook AI Similarity Search, is a powerful library designed to efficiently perform similarity search and clustering tasks on large-scale datasets. FAISS incorporates state-of-the-art techniques, including index structures like Inverted Multi-Indexes and PQ-codes, to enable fast and accurate similarity searches. With its ability to handle high-dimensional vectors and effectively scale to billions of data points, FAISS has become an invaluable tool for various applications, such as recommendation systems, image and video search, and natural language processing tasks.
NMSLIB
NMSLIB, which stands for Non-Metric Space Library, is a versatile open-source library developed to handle similarity search problems efficiently. It provides an extensive collection of state-of-the-art indexing and search algorithms, allowing users to explore and evaluate various approaches for similarity search tasks.It allows for indexing high-dimensional data efficiently, making it suitable for applications such as recommendation systems, image and text search, and genomic data analysis. With its user-friendly interface and robust performance, NMSLIB has become a popular choice among researchers and developers for tackling complex similarity search challenges.
What to look for?
For example, we can look at the OpenSearch implementations of the NMSLIB and FAISS with HSNW
| Traits | NMSLIB | FAISS |
|---|---|---|
| Maximum Dimensions | 16000 | 16000 |
| Similarity Metrics |
|
|
| Vector Volume | Billions | Billions |
| Query Latency | Low latency & high quality | Low latency & high quality |
| Memory Consumption | High | High |
When considering a search algorithm for approximate search, there are several key factors to keep in mind. Here are few questions to ask:
- How many dimensions does the algorithm support?
- Which similarity metrics does the algorithm support and which one does it most optimized on?
- How much volume it can support?
- How is the latency?
- How is the memory consumption?
Vector Database
A vector database refers to a specialized database that is specifically designed to store and manage high-dimensional vectors. Unlike traditional databases that primarily handle structured data, a vector database focuses on efficiently storing and retrieving vectors, which are numerical representations of objects or data points in a multi-dimensional space. It provides functionalities for indexing, searching, and manipulating vectors, making it an essential tool for various applications such as machine learning, data mining, image recognition, and recommendation systems. By employing dedicated indexing structures and search algorithms, a vector database enables fast and accurate similarity searches, allowing users to find relevant vectors based on their proximity in the high-dimensional space.
Here are some examples of Vector Databases:
- Pinecone, a commercial solution that is fully-focused on Vector Database
- Milvus, an open source implementation of Vector Database
- PGVector, a PostgreSQL Plugin that allows users to use Postgre as Vector Database
- OpenSearch Neural Search Plugin
- ElasticSearch Vector Search
Conclusion
In conclusion, by carefully selecting the appropriate components and designing a suitable architecture, it is possible to create a custom neural search tailored to your preferences and choice of programming language. Moreover, neural search is not limited to text-based search alone; it can also be extended to other media formats such as audio, images, and videos. The key principle is to convert these diverse mediums into a set of unique identified numerical representations. By leveraging the right tools, such as indexing, storage, and search mechanisms, it becomes feasible to effectively index, store, and search among these varied data types. The possibilities for neural search are vast and can greatly enhance the exploration and retrieval of information across different modalities.
How can we help?
At Sonne Technology, we specialize in providing cloud-based solutions and consultancy services to businesses seeking to leverage the latest trends in technology. Our core focus is on creating Function as a Service (Serverless) products that offer customers an easy-to-manage, stress-free experience. Our team comprises of highly skilled professionals who are passionate about delivering top-notch services to our clients.
We understand that for businesses, flexibility and cost-effectiveness are key, and we strive to deliver solutions that meet these requirements. To this end, we specialize in working with startups and SMEs, providing personalized services that are tailored to meet their specific business needs.
Our expertise covers several areas, including setting up OpenSearch/ElasticSearch clusters, applying migrations from keyword search index, and optimizing search pipelines in large scale. We have experience in developing innovative solutions that help businesses achieve their search objectives efficiently and effectively.
Get in touch with us today to find out how we can help take your business to the next level with our innovative cloud-based solutions and consultancy services.
