

Introduction
In the bustling ecosystem of machine learning applications, classification tasks unequivocally hold a prominent role across various industry verticals. From detecting fraudulent transactions in finance to churn determination in ecommerce, classification models aid in swiftly categorizing data points into distinctive classes or groups. However, a common challenge emerges when these groups are not represented equally in the dataset, leading to what's known as class imbalance.
Due to the imbalanced nature of the dataset, the classification model may prioritize the majority class and neglect the minority class, resulting in inaccurate predictions for the less common category. This blog delves into the realm of imbalanced classification, exploring ingenious methodologies to handle disproportion.
Understanding Imbalanced Classification
Imbalance occurs when the distribution of classes in a dataset is uneven, with one class significantly outnumbering the other(s). In such cases, standard classification algorithms may exhibit a bias toward the majority class, resulting in poor performance on the minority class, which is often the class of interest.
Why Address Imbalance?
In business applications, the rarity of an event often correlates with its importance. For instance, predicting equipment failure within a manufacturing plant — while infrequent — is crucial to maintain operational continuity and safety. Similarly, the identification of fraudulent activities among millions of legitimate transactions can save a company significant revenue.
Techniques to Overcome Class Imbalance
Resampling Techniques
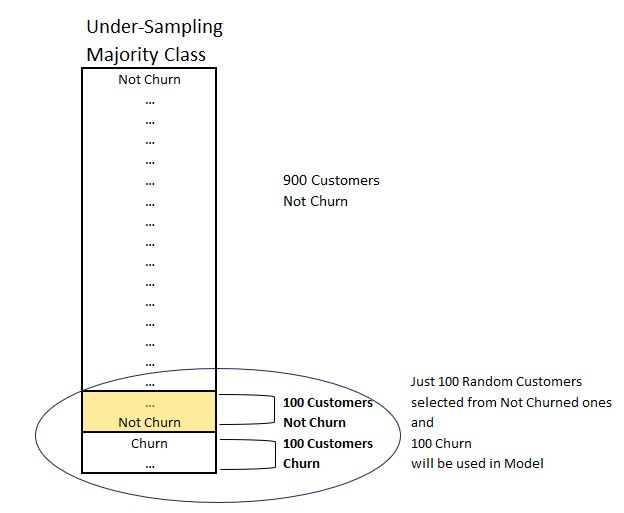
Under-Sampling the Majority Class
This method involves removing instances from the majority class to balance the class distribution. While simple, under-sampling can lead to loss of valuable information.
Example: A credit card company might have 98% legitimate transactions and 2% fraudulent ones. Under-sampling would reduce the number of legitimate transactions to match fraudulent ones, potentially losing insights into legitimate transaction patterns.
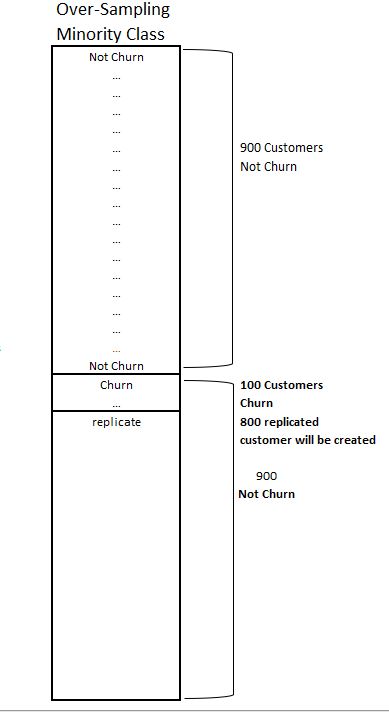
Over-Sampling the Minority Class
In contrast to under-sampling, over-sampling replicates minority class instances. However, it can increase the likelihood of overfitting, where the model learns the noise in the training data.
Example: In a marketing dataset where only 5% of customers respond to a campaign, over-sampling those who responded can help create a balanced dataset, ensuring the model pays adequate attention to the responder class.
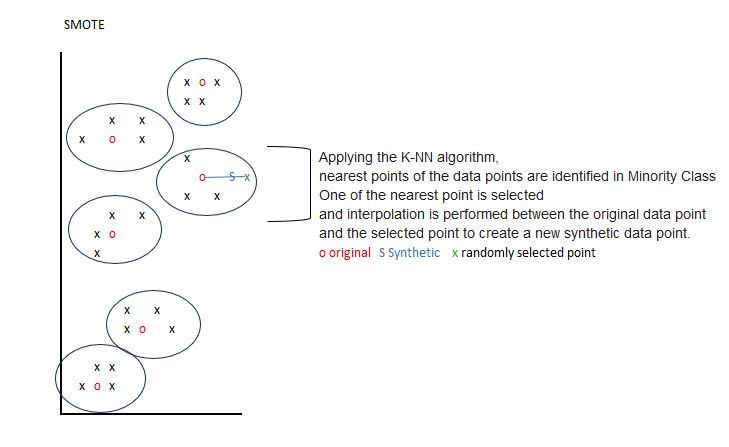
Synthetic Data Generation (SMOTE)
SMOTE (Synthetic Minority Over-sampling Technique) generates new, synthetic examples of the minority class using a combination of interpolation and existing data points. This helps create a more generalized model.
Example: An insurance firm may use SMOTE to generate synthetic claims representative of rare incidents, thereby improving their system's ability to detect potential future rare claims accurately.
Cluster Centroid Method
The Cluster Centroid method is a type of under-sampling technique that involves condensing the majority class to match the minority class count. Unlike random under-sampling, which may discard potentially valuable data points, the Cluster Centroid method preserves information by representing the majority class with the centroids of clusters identified within the class. Here's how it works:
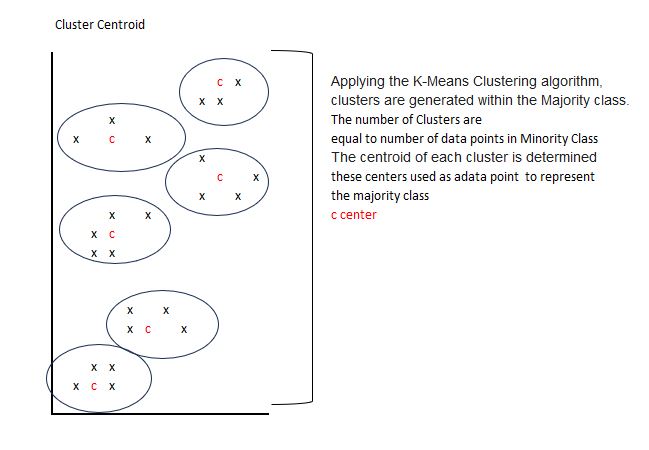
Example: A telecom company is trying to predict which of their customers might churn in the near future. Their dataset is heavily imbalanced, with a large majority of customers who remain subscribed and a small minority who churn. By applying the Cluster Centroid method, the company clusters the data of the customers who stay, and each cluster's centroid becomes the summary of those customers' behaviors. This method ensures that the diversity within the majority class is preserved to some extent and is captured by the centroids, thereby not losing out on the nuances of customer behavior patterns.
Algorithm-Level Approaches
Cost-Sensitive Learning
Here, the algorithm is modified to make the misclassification of minority class instances more penalizing than misclassifications of the majority class, essentially assigning different costs to different types of errors.
Example: In predictive maintenance, the cost of missing a machine failure (a false negative) is much higher than misidentifying a functioning machine as failing (a false positive). Cost-sensitive learning can adjust the algorithm's focus accordingly.
Ensemble Methods
Ensemble methods, such as Random Forest or Gradient Boosting, combine multiple models to improve the overall performance. These can be made imbalance-aware by adjusting their learning process to pay more attention to the minority class.
Example: An e-commerce platform uses an ensemble of models to predict customer churn. By focusing on the small segment of customers at risk of churning, the ensemble model can more accurately target retention measures.
Business Examples of Imbalanced Classification
Financial Sector: Fraud Detection
Financial institutions employ machine learning models to identify fraudulent transactions. Given that fraud events are rare compared to legitimate transactions, applying resampling or ensemble techniques can greatly improve the detection rates, saving potentially millions from fraudulent losses.
Healthcare: Disease Prediction
When diagnosing diseases, especially rare ones, it's common for patient datasets to exhibit class imbalance. Advanced synthetic data generation techniques like SMOTE are particularly valuable in this field, helping train reliable diagnostic models which can save lives with early detection.
E-Commerce: Customer Churn Prediction
E-commerce companies are keen on predicting which customers may leave their service. The majority of customers typically stay with the service, so churn prediction is an imbalanced problem. Machine learning models that adequately handle this imbalance can guide intervention strategies, enhancing customer retention.
Manufacturing: Predictive Maintenance
Predictive maintenance models forecast equipment failures before they occur. Failures are less frequent in comparison to normal operation data, making this a prime case for employing cost-sensitive learning or modified ensemble methods to prevent costly downtimes.
Conclusion
Balancing the scales in imbalanced classification not only enhances the performance of machine learning models but also ensures that critical and often costly events aren't overlooked. By strategically employing one or more of the discussed techniques, businesses can extract meaningful insights from their data, irrespective of class distribution, and make informed decisions that drive success in an increasingly data-driven world.
