

Defining the Problem
ChekRite Pty. Ltd. is a startup based in Australia that offers checklist solutions for the manufacturing sector. As the demand for these solutions continues to grow, the company has been working on developing a second version of its application from scratch. However, some of the legacy codebase still needs to be maintained to meet the current demand while the new version is being developed.
The legacy framework that ChekRite is using was developed back in 2011, when PHP-5 and CakePHP v2.x were the norm. Unfortunately, this codebase was not designed with microservices in mind. As a result, the entire application is in a monolithic state, making it difficult to scale horizontally. Despite vertical scaling, demand has outpaced the capacity of the system, leading to long wait times for customers. In some cases, customers are waiting up to four hours for their jobs to be processed.
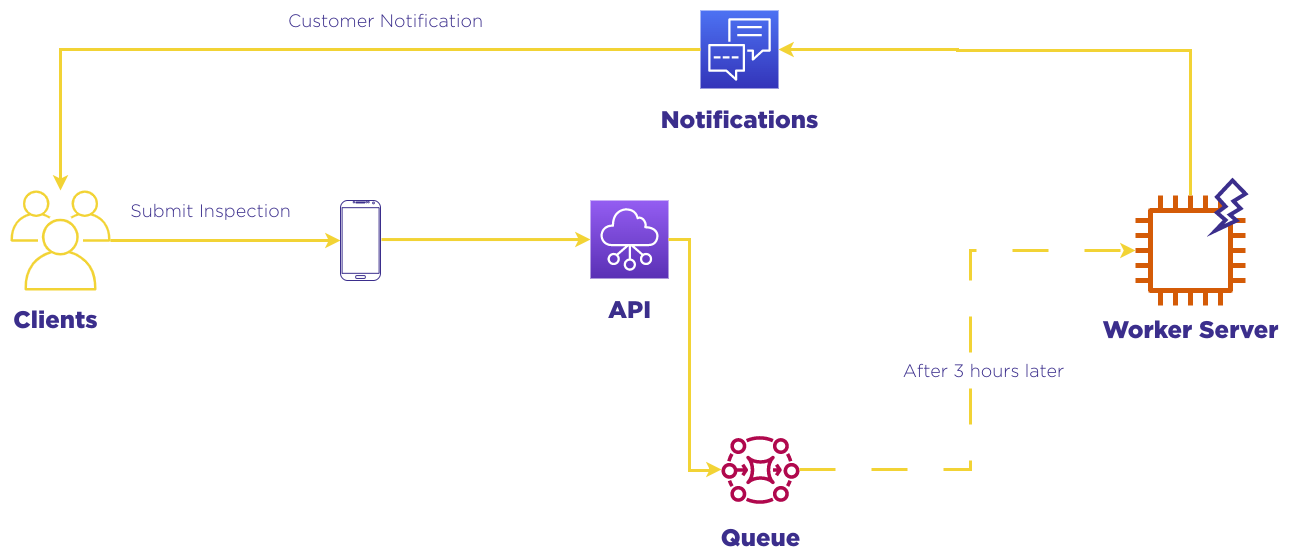
To address this issue, ChekRite needs a more efficient solution that allows for horizontal scaling and the dynamic allocation of resources. The solution should be able to process jobs quickly, matching the demand in real-time. Furthermore, the solution should be able to handle the load of the current demand and scale accordingly, while also being cost-effective.
The objectives of ChekRite's legacy codebase renovation are clear and specific. The primary goal is to reduce job processing time from submission to completion to 10 minutes, providing a much faster and more efficient experience for customers. Additionally, the system should not require any maintenance, freeing up time and resources for other business-critical tasks.
Another objective is to integrate the new system with the current Continuous Integration and Continuous Deployment (CI/CD) process that ChekRite has in place. This will ensure that the new solution is deployed quickly and seamlessly, with minimum disruption to the existing workflow.
Finally, ChekRite is also looking to optimize the costs associated with the legacy codebase. By implementing a more efficient solution that can scale dynamically to match the demand, ChekRite hopes to reduce operational costs while still providing the necessary capabilities for the business to grow and thrive. Our team was exploring various serverless architectures that can provide the necessary scalability, performance, and cost-effectiveness to achieve these objectives.
A Proposed Solution
After facing the challenges presented by the legacy codebase, We have identified a potential solution to modernize its system and meet the objectives outlined earlier. The proposed solution is to Dockerize the worker logic and deploy them on ECS Fargate for each queue. This approach will allow the system to auto-scale based on the size of the queue, providing the necessary resources to process jobs quickly and efficiently.
One of the key advantages of Dockerizing the system is that it allows for a more modular approach to development and deployment. Each worker logic can be packaged as a separate container, making it easier to manage and update individual components. Additionally, Docker containers provide a higher level of isolation and security, reducing the risk of conflicts and vulnerabilities.
ECS Fargate is a natural choice for deploying the containers, as it provides a fully managed and scalable compute engine for running containers. With Fargate, ChekRite can take advantage of auto-scaling capabilities to dynamically allocate resources based on the size of the queue. This approach ensures that the system is always running at peak efficiency, with the necessary resources allocated to handle the current demand.
In addition to the benefits of Dockerizing and using Fargate, the proposed solution also aligns with ChekRite's existing CI/CD process. By leveraging the power of Bitbucket Pipelines, ChekRite can automate the deployment process, making it faster and more reliable. This will help to ensure that the new solution is deployed seamlessly, with minimal disruption to the existing workflow.
Another advantage of the proposed solution is that it allows for more efficient resource utilization, which can help to optimize costs. With auto-scaling capabilities, the system can adjust the number of resources allocated to each queue based on the actual demand. This means that ChekRite can avoid over-provisioning resources, or shut down everything when there is no utilization at all.

Despite the promise of the proposed solution, as with any complex system, there are potential complications that need to be carefully considered and addressed. In the case of ChekRite's legacy codebase renovation, there are four complicating factors that our team needs to navigate in order to successfully implement the proposed solution.
Complications
Complication 1 - Dockerization itself
As the ChekRite team began to implement the proposed solution, they quickly realized that there were several complicating factors that needed to be addressed. The first major challenge was how to run PHP5 in a container, given that nearly every major operating system has discontinued support for this version. Additionally, the current system was running on CentOS 6, which further limited the available options.
To solve this problem, team turned to Remi's RPM Repository, which offers a range of PHP versions that can be deployed on supported operating systems and maintained accordingly. After some experimentation, our team decided to use Amazon Linux 2, which supports RHEL7 based RPMs, along with Remi's PHP. With some tweaking and configuration, our team was able to get a running container that could handle PHP5.
While this solution may sound straightforward, the reality was far from easy. Our team encountered numerous dependency problems, including missing PHP modules and library dependencies. However, by leveraging Remi's repository and carefully troubleshooting each issue, the team was ultimately able to overcome these challenges.
Sample PHP 5.6 Installation for AL2:
FROM public.ecr.aws/amazonlinux/amazonlinux:2
RUN yum update -y
RUN yum install -y yum-utils
RUN yum install -y wget
RUN yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
RUN yum install -y https://rpms.remirepo.net/enterprise/remi-release-7.rpm
RUN yum-config-manager --setopt="remi-php56.priority=5" --enable remi-php56
RUN yum install -y php
In conclusion, the process of running PHP5 in a container can be complicated and time-consuming, particularly when dealing with legacy systems. However, by utilizing specialized repositories like Remi's and carefully addressing each dependency issue, it is possible to create a functional container that can effectively handle PHP5.
Complication 2 - Fargate Service never goes to 0
The second complication that the team encountered during the implementation of the proposed solution was related to the auto-scaling rules of the ECS service on Fargate. Specifically, they discovered that there was no way for the ECS service to scale down to 0 while there were no messages on the queue. This presented a challenge, as it meant that the system would continue to run even when there was no demand, leading to unnecessary costs and resource usage.
To address this issue, our team explored various strategies and best practices for auto-scaling rules. One of the most common approaches involves creating two separate alarms and setting contrary rules, so that one alarm is in alarm state when there are messages on the queue, and the other alarm is in healthy state when there are no messages. However, this approach did not work in the ChekRite case, as there was no way to set the healthy state to 0.
To solve this problem, Our team came up with a creative solution. They realized that they could select a number that would never be available in the queue, and set that number as the healthy state. Specifically, the team set the healthy state to `-1`, as this value would never occur in the queue. By doing so, team was able to ensure that the alarm would never be in a healthy state, and that every single change would be directly propagated to the auto-scaling rules.

This approach allowed our team to utilize one alarm per queue, and initiate step scaling by the message queue. While this solution may seem unconventional, it was an effective way to address a complex challenge and ensure that the system could auto-scale efficiently and cost-effectively.
Complication 3 - Worker Storage Network
Despite the progress made in implementing the proposed solution, our team encountered a fundamental issue related to the email report attachments. Specifically, they discovered that there were two distinct queues for preparing and sending the report, and that there was no shared file location between the workers. In a monolithic system, this would not have been an issue, as the report could be prepared and a message sent to the mail worker with the file location pointer. However, in the current system, this was not possible.
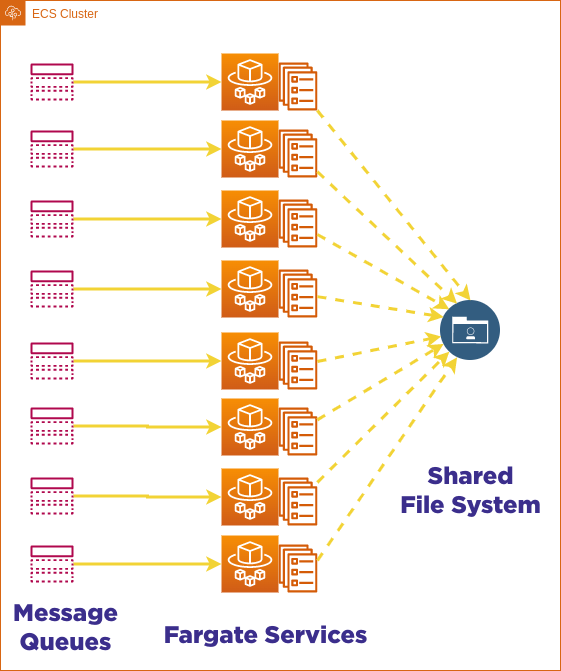
To address this issue, our team decided to create a single file sharing system using Amazon Elastic File System (EFS). With EFS, every Fargate task spins up with a volume attached to its /tmp directory, allowing the processing worker to export the report to the shared folder, and the mail worker to read from there. This approach ensures that the report attachments are properly shared and accessible between the two distinct queues.
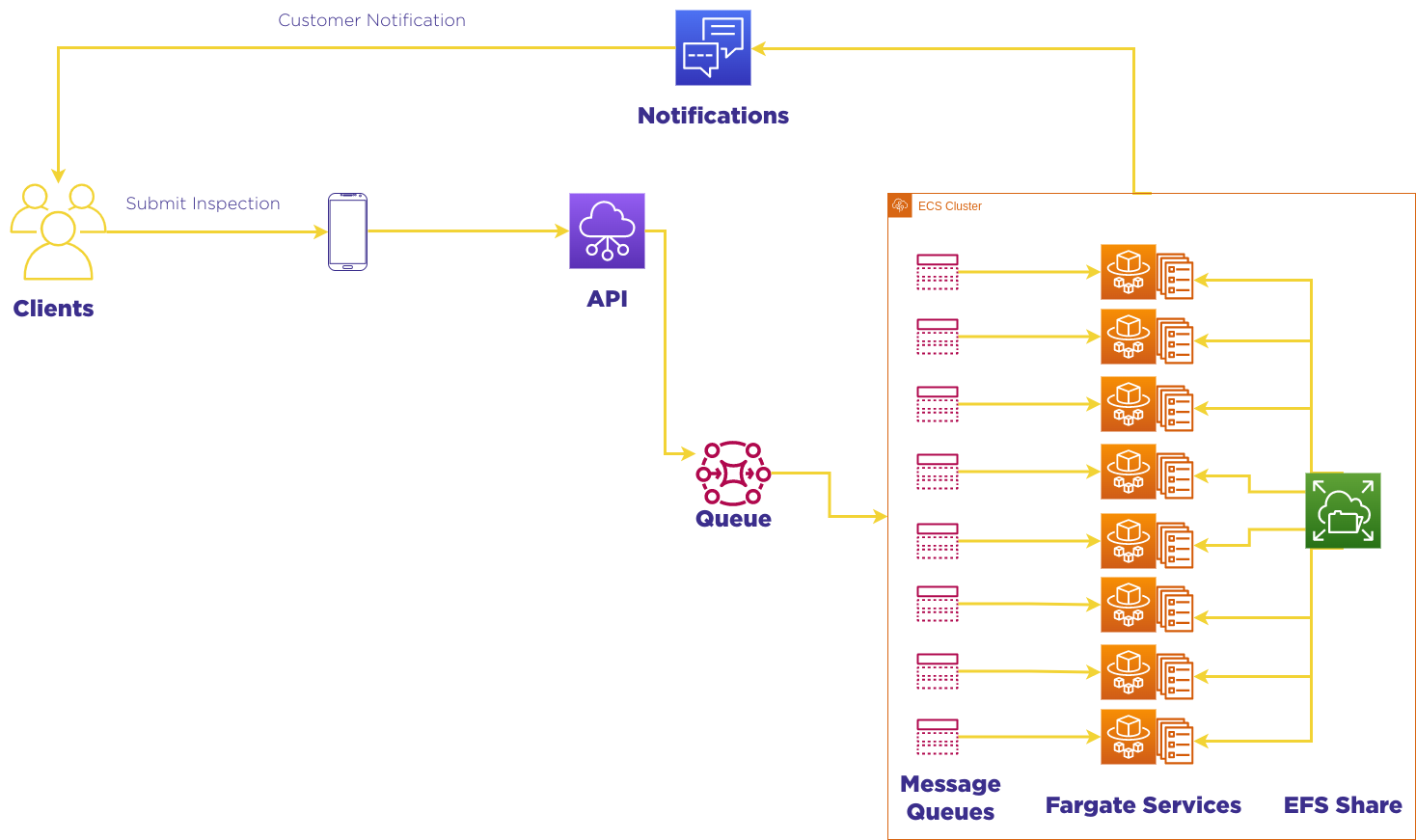
In the end, the EFS solution proved to be an effective way to address the fundamental issue with the email report attachments. By creating a single file sharing system, the team was able to ensure that the report attachments could be properly prepared and sent without any complications. This solution highlights the importance of careful planning and implementation when dealing with complex systems, and the value of creative solutions in addressing fundamental issues.
Complication 4 - NAT Gateway Data Processing Charges
Despite the successful launch of the new system on production, the team encountered a major issue related to skyrocketing costs. After careful investigation, our team discovered that the charges were due to NAT Gateway Data Processed charges, which indicated a significant amount of network activity both inbound and outbound. This was unexpected, as there had been no changes to the customer-facing site, and the only major change was the switch to a Docker-based system.
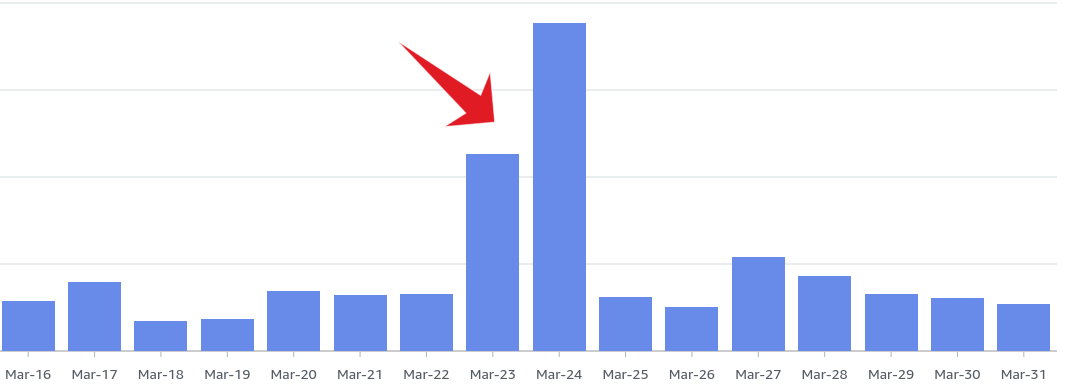
To get to the root of the problem, our team looked at CloudWatch metrics to try and find any correlation. They discovered that there was a high correlation between the number of running tasks on ECS and the NAT Gateway Data Processing packets. This was concerning, as communication between ECS and ECR should be free of charge, and the network activity between the NAT Gateway and other parties should not have been counted as Data Processing.

To address this issue, the team quickly reconfigured the system on a new network subnet that was not reachable behind the NAT Gateway. This helped to eliminate the NAT Gateway Data Processing charges, and significantly reduced the overall costs. Fortunately, we were able to catch this issue within a day, which limited the damage that could have been caused.
Thanks to the prompt action of the team and the support of AWS, the issue was ultimately resolved, and the charges were waived. This experience highlights the importance of closely monitoring costs and network activity, particularly when implementing new systems or making major changes to existing ones. By staying vigilant and proactive, the team was able to successfully navigate this complication and continue to provide high-quality checklist solutions to its customers.
Complication 5 - RabbitMQ Bottlenecks
Our team had successfully launched their new system, and things were looking great - until the third day. Suddenly, the system stopped processing messages, and the queue began to grow larger by the minute. This was a major issue, as there were over 100 containers running at the time, but only 2 messages were processed in 10 minutes. The team knew that something was seriously wrong.
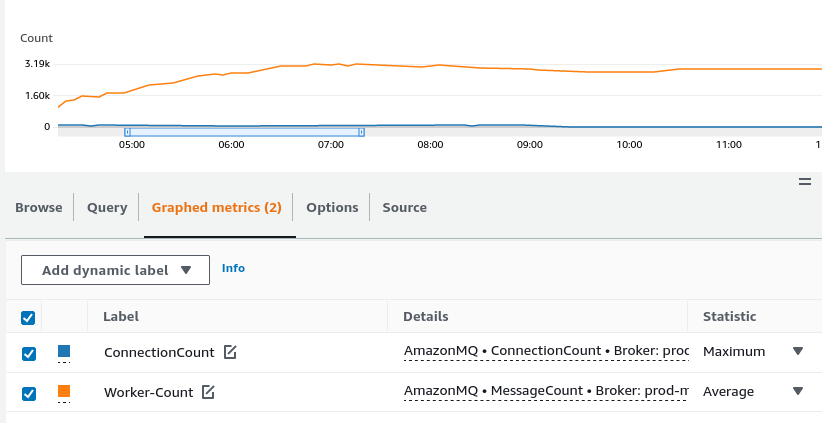
Acting quickly, we have shut down the system and rolled it back to identify the issue. They found that there were many `Broken pipe()` errors from the workers, which indicated a problem with the RabbitMQ connection. For three long days and sleepless nights, the team worked tirelessly to identify the root cause of the issue.
Finally, they stumbled upon a breakthrough. They discovered that the RabbitMQ connection was the bottleneck, and it could not handle more than 50 connections at once. If the connection number went above this threshold, the system could not process the messages, and the processing would stop altogether.
With this discovery in hand, the team adjusted the auto-scaling numbers to allow only 50 connections at once. This simple solution resolved the issue and saved the day. We were thrilled to have found the root cause of the problem and to have successfully addressed it. They were grateful to have a team of skilled professionals who were able to work together to find a solution, and to be able to continue providing high-quality checklist solutions to their customers.
Conclusion
Currently, ChekRite has expanded the capacity of their workers by an incredible 50 times. This is a remarkable achievement that has significantly increased the efficiency and processing power of the system, allowing to handle more requests and scale more effectively. By expanding the capacity of the workers, the ChekRite has been able to process more messages in less time, significantly reducing the queue time from a staggering 4 hours to a mere 8 minutes on average. This is a major improvement that has had a significant impact on the overall performance and effectiveness of the system.
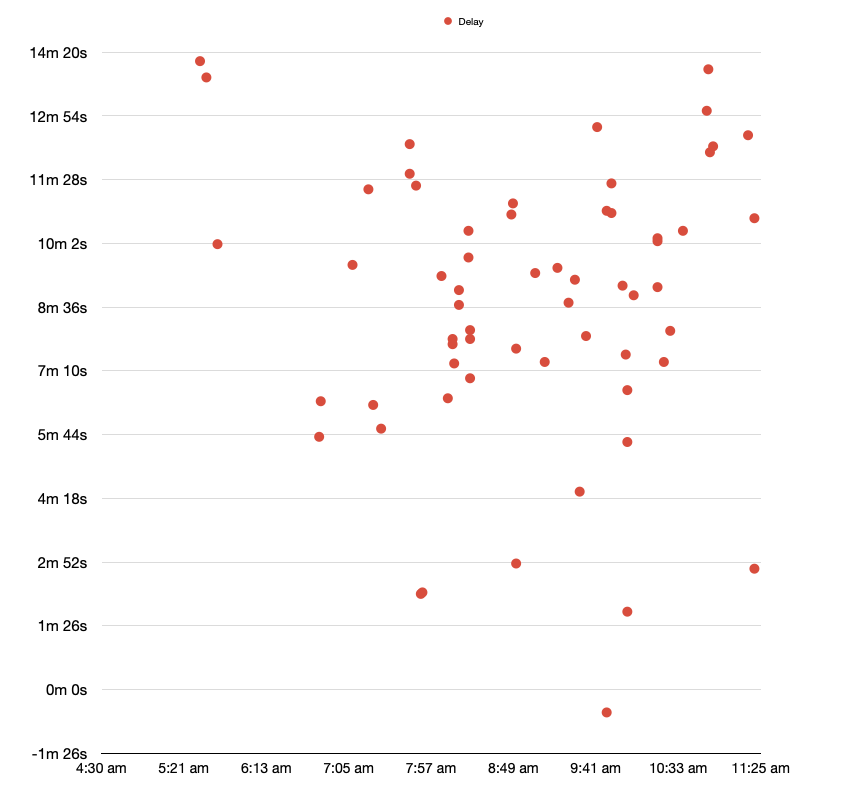
Through innovative solutions and tireless effort, our team able to overcome numerous challenges, including running PHP5 in a container, addressing issues with email report attachments, and tackling skyrocketing costs related to network activity. Team worked tirelessly to optimize their systems to achieve outstanding results.
With the constant evolution of technology, businesses need to be able to adapt and thrive in order to remain competitive. ChekRite has done just that by investing in their infrastructure, streamlining their processes, and improving their products. As a result, they are now in a stronger position to serve their customers and meet their needs. Overall, the future looks very promising for ChekRite. With the improvements they have made, they are well-positioned to continue providing innovative checklist solutions to their customers. The team's hard work and dedication have paid off, and the company is now poised for even greater success in the years to come.
Who are we?
Sonne Technology was founded in 2021 with the mission of providing cloud based solutions and consultancy services to businesses. Our focus is on creating Function as a Service (Serverless) products that offer customers an easy-to-manage, stress-free experience. We specialize in working with startups and SMEs, where flexibility and cost-effectiveness are key. Our team is ready to take on any challenge in an ultra-agile environment. We are dedicated to creating a community of growth and mutual support.
