

Introduction
With 2023 being heralded as the breakthrough year for generative AI, experts predict continued growth in 2024. According to recent estimates by
Straits Research - Yahoo Finance
and
McKinsey Digital - McKinsey & Company
, the global generative AI market is projected to reach up to $18.2 billion USD by 2024, with potential impacts ranging between $2.6 trillion and $4.4 trillion USD across various sectors. This blog post aims to provide insights into the industry implications and emerging trends in generative AI research likely to unfold in 2024.
Realm of Generative AI in 2024
Rise of the Multimodal
In recent years, deep learning has made significant progress in both language and vision models, each excelling in their respective domains. However, these models were limited to their individual modalities, lacking the ability to integrate information from other sensory inputs. To address this limitation, multimodal models have emerged, combining the strengths of language and vision models to create a powerful fusion of both. These models have the potential to revolutionize various fields, such as:
-
Prototyping with sketches
 SawyerHood/draw-a-ui - GitHub
SawyerHood/draw-a-ui - GitHub
-
Visual Guidance through grounding
AI Based Yoga Trainer - IEEE Xplore
-
Understanding sign language
 Multi-modal Sign Language Recognition - Arxiv
Multi-modal Sign Language Recognition - Arxiv
Currently, there are several state-of-the-art commercial models available, such as
Google’s Gemini Ultra Vision
and
 OpenAI’s GPT-4-Vision
. However, the open-source community is rapidly advancing in this field, offering a range of models that can be used for diverse applications. Some notable open-source models include:
OpenAI’s GPT-4-Vision
. However, the open-source community is rapidly advancing in this field, offering a range of models that can be used for diverse applications. Some notable open-source models include:
-
Qwen-VL From AliBaba Cloud - Hugging Face
-
-
-
-
-
These cutting-edge models represent a significant breakthrough in multimodal research, enabling the integration of visual and linguistic information to enhance understanding and interaction. With the continued development of multimodal models, we can expect to see exciting innovations in various industries, transforming the way we communicate, collaborate, and solve complex challenges.
Advancements in Video Models and Multimodal Fusion of Video+Audio Models
The year 2023 marked a significant milestone in the development of Text-to-Video (TTV) and Image-to-Video (ITV) models, with the introduction of pioneering works such as
hotshotco/Hotshot-XL - Hugging Face
or
stabilityai/stable-video-diffusion-img2vid-xt - Hugging Face
. These models have paved the way for the next generation of TTV and ITV models, which are expected to reach the level of stability and sophistication achieved by Stable Diffusion XL in Text-to-Image and Image-to-Image tasks.
As we move forward into 2024, several novel approaches are being explored to further advance the capabilities of TTV and ITV models. For example:
-
Emu Video's method involves generating an initial image followed by motion derived from the initial prompt and image
Emu Video - Arxiv
-
VideoBooth leverages image embedding to incorporate an image within the video itself
VideoBooth - Arxiv
-
MTVG divides prompts into segments to create a visually engaging story
MTVG - GitHub
While these models are capable of producing impressive motion pictures, they are currently limited to generating mute videos. To overcome this constraint and achieve truly immersive experiences, researchers are turning their attention to multimodal transformer architectures that can seamlessly integrate audio and video generation. Google Research Team's
VideoPoet - Google Research
model represents a promising step in this direction, capable of creating videos that adhere to the original multimodal inputs, complete with synchronized audio.
Although the open-source community is still in the early stages of developing multimodal transformer architectures for video and audio, we anticipate significant strides in 2024, with the emergence of the first open-source models that can effectively fuse video and audio generation. As these technologies continue to evolve, we can expect nothing short of a revolution in the way we experience and interact with multimedia content.
The Role of DevOps in Implementing and Managing Generative AI Models or GenAIOps
With the rapid growth of generative AI, new models are emerging at an unprecedented rate, and organizations are struggling to keep up. To address this challenge, there is a pressing need for continuous assessment of models against their designated tasks and seamless integration of new models into existing systems. At a high level, the following components are required to streamline this process:

Currently what is missing on this diagram:
- Alerting mechanisms that notify stakeholders when a newly developed model surpasses the performance of the current leader in a leaderboard.
- Well-defined internal key performance indicators (KPIs) that align with business objectives.
- Access to relevant test data tailored to specific tasks.
- Ability to swap models without modifying the underlying codebase.
While the latter is relatively straightforward to achieve through the use of libraries such as
Hugging Face Transformers
or
 LangChain
, the former three requirements necessitate a deeper understanding of generative AI and its practical applications within organizations. As such, DevOps teams must invest time in learning about these technologies and developing strategies to evaluate and compare models effectively. By 2024, we anticipate the development of dedicated tools that automate these processes, augmenting existing DevOps solutions.
LangChain
, the former three requirements necessitate a deeper understanding of generative AI and its practical applications within organizations. As such, DevOps teams must invest time in learning about these technologies and developing strategies to evaluate and compare models effectively. By 2024, we anticipate the development of dedicated tools that automate these processes, augmenting existing DevOps solutions.
3D Gaussian Splatting or 3D Asset Creation with GenAI
In 2023, various renowned providers such as
stabilityai/stable-zero123 - Hugging Face
,
openai/shap-e - Hugging Face
and
 Zero123 - Columbia University
introduced their initial 3D asset creation models, utilizing large amounts of annotated 3D dataset like
Zero123 - Columbia University
introduced their initial 3D asset creation models, utilizing large amounts of annotated 3D dataset like
allenai/objaverse - Datasets at Hugging Face
. These models were trained using vectors to represent assets. A sample image-to-3D asset output is shown below:

Nevertheless, a new approach called "3D Gaussian Splatting" is set to revolutionize this workflow. This method produces highly realistic and performance-optimized 3D assets from multiple images of the desired object. Exciting research in 3D space has been conducted, including:
-
Gaussian Head Avatar or real-time reflection on an avatar
-
Real-time human scan through Gaussian means
-
Handling light reflections with Gaussian
These groundworks have led to models like
DreamGaussian - GitHub
, capable of generating 3D assets using Gaussian splatting, sans the necessity for vector creation, which requires substantial resources. It is expected that in 2024, Gaussian models will dominate the 3D asset creation space by training a foundational model using current 2D images and 3D asset datasets, alongside acquiring diffusion proficiency within its latent pipeline.
Hugging Face offers an excellent blog that delves into the details of how 3D Gaussian Splatting functions. Here is the link:
Introduction to 3D Gaussian Splatting - Hugging Face Blogs
Acceleration on Hardware Accelerators
At the beginning of 2023, the
Global chip shortage - Wikipedia
came to an end, and as a result, there has been a surge in the number of hardware manufacturers, particularly those producing hardware accelerators. Some notable examples include:
-
AWS Trainium Chip &
-
 Intel Habana Gaudi 2
Intel Habana Gaudi 2
-
 FuriosaAI WARBOT
FuriosaAI WARBOT
-
Google Cloud's TPU v5
-
AMD's Instinct Series
-
NVIDIA's H200
With so many new players in the market, companies must be vigilant in selecting the right hardware for their AI implementations, both on-premises and in the cloud.
When making such decisions, there are three crucial questions that should be asked:
-
Does the workflow necessitate real-time inference or batch processing?
This query addresses the urgency of the task at hand. If real-time inference is required, the millisecond per token (latency) metric should be examined. However, if batch processing is sufficient, the token per second (throughput) metric should be considered.
-
What is the token per dollar value of this hardware?
This inquiry delves into the realm of optimization. It's important to consider the first question's response while evaluating the ideal hardware for the job. Although the most advanced hardware may provide the quickest performance, it may also be prohibitively pricey. Conversely, settling for subpar equipment merely because it's less expensive may result in extended production times, ultimately increasing expenses. The primary goal is to maximize the "token per dollar" ratio based on the answers to the first question.
-
How much effort is required to deploy this hardware?
This question focuses on the human resource requirements of utilizing the hardware. While the hardware itself can be optimized for the first two criteria, other factors come into play. For instance, altering the deployment strategy or restricting certain aspects may negate any potential benefits. Additionally, some situations may demand the use of "fixed input shapes", which limits input sizes indefinitely and may not align with the organization's goals.
In conclusion, choosing the right hardware for AI applications is a critical decision that can significantly impact the success of a project. By considering the three key factors discussed here organizations can make informed decisions that balance performance, cost, and efficiency. Whether opting for a high-performance GPU or a more affordable accelerators, the right hardware choice can help businesses stay ahead of the competition and achieve their AI goals. By carefully evaluating the available options and understanding the unique demands of their AI workloads, organizations can ensure they have the necessary horsepower to drive their AI initiatives forward.
Around the World with Geo-Spatial Models
Although navigation apps are among the most popular smartphone applications, the potential of generative AI in the field of geo-spatial models remains largely untapped. However, recent advancements have been made in this area, including the development of "Prithvi", the first geo-spatial foundational model, courtesy of IBM and NASA (
ibm-nasa-geospatial/Prithvi-100M - Hugging Face
). Additionally, a notable paper was published at the end of the year that leverages multimodal models (
Charting New Territories - Hugging Face Papers
) for geographic applications.
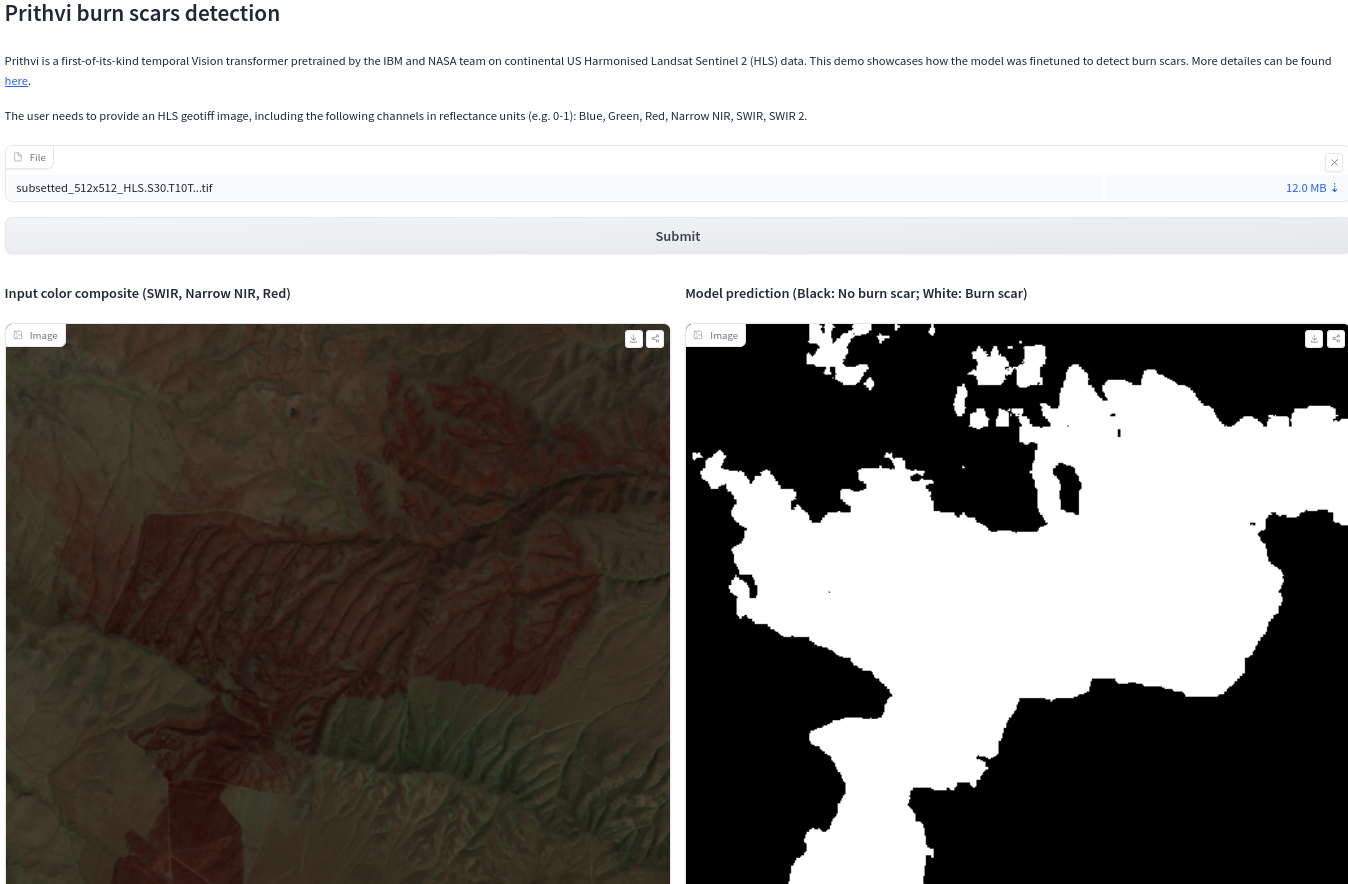
Despite these developments, the use of geo-spatial models remains relatively unexplored territory. As such, we can anticipate significant progress in this field, particularly in areas such as:
- Optimizing logistics through real-time satellite imagery
- Forecasting urban planning
- Disaster response management
- Geo-aware decision making
In conclusion, the potential of geo-spatial models in various industries is vast and diverse.v With the continued development of advanced technologies and increasing accessibility to spatial data, the future of geo-spatial models looks bright. It is up to us to harness this power and create solutions that will revolutionize the way we live and work. By embracing the capabilities of geo-spatial models, we can build a better tomorrow, today.
IoT, Small Language Models, Quantization & Edge Device Management
A decade ago, the Internet of Things (IoT) was at the peak of its popularity, but it has since faded from the spotlight. However, it is now making a comeback with even greater potential. Previously, IoT's primary strength lay in enabling devices to communicate their state over the internet and storing data in the cloud.
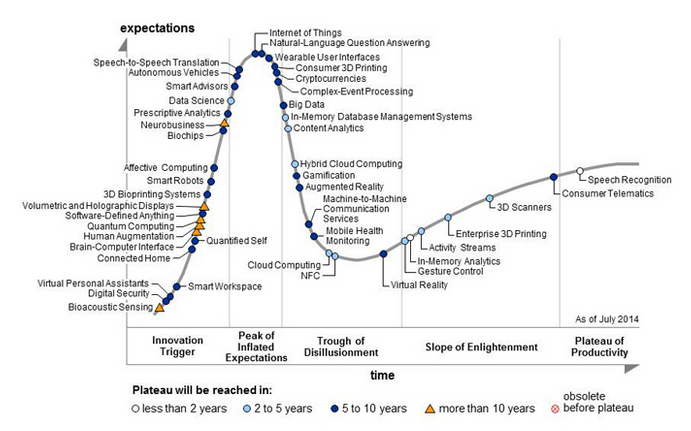
In recent times, we have seen the emergence of Small Language Models (SMLs), which enable us to embed intelligence into edge devices without requiring excessive resources or an internet connection. By providing appropriate prompts, these models can function as intelligent agents in the field. Noteworthy examples include:
-
-
-
Thanks to advanced quantization techniques, it is now possible to run large language models like LLaMa-2 on microcontrollers, as demonstrated by projects such as
llama4micro - GitHub
. As these models become more widespread, effective edge AI management systems will be crucial for managing and deploying them efficiently. Services like
In 2024, Businesses must evaluate their needs carefully, deciding whether to process data on the client or server side, and choosing the best approach based on their specific requirements. This will help them optimize their architectures and unlock the full potential of IoT and SLMs.
Conclusion
In conclusion, the emerging trends in Generative AI have opened up exciting possibilities for businesses to leveraging AI's creative potential. If you're interested in exploring these opportunities, Sonne Technology is here to help. As a leading provider of precision-crafted AWS solutions, we specialize in tailoring our AI-powered expertise to meet the unique needs of our clients. Our focus on delivering Function as a Service (serverless) products ensures a seamless, hassle-free experience. We prioritize flexibility and cost-effectiveness, making our services accessible to startups and SMEs. Our team thrives in an ultra-agile environment, allowing us to quickly adapt to changing demands and tackle any challenges that come our way. Join us and transform your cloud experience with the power of Generative AI.
